News
Guangdong BAIDU Special Cement Building Materials Co.,Ltd— 新闻中心 —
中国和中兴科学技术大学提出了一种新的训练后
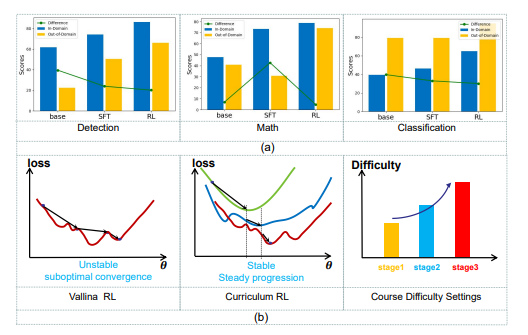 本文的第一组是中国科学技术大学的硕士和医生研究Huilin Deng。他的研究方向是多模型的视觉理解,增强的推理(R1研究)和异常发现。在Tai,Tase,ICCV以及其他期刊和会议等期刊上发表论文。近年来,随着大语言模型(LLM)的快速发展,多模式理解领域产生了前所未有的发展。诸如OpenAI,InternVL和QWEN-VL系列之类的最先进的视觉模型显示了处理复杂的视觉文本任务的剩余功能。但是,这些成就主要取决于大型模型的扩展(32B参数),从而在环境中产生了巨大的障碍。因此,如何通过有效的训练后范式缩小小型多峰模型和大型模型之间的性能差距是紧迫的PROblem。当前,VLM中的主要培训方法是通过微调(SFT)管理的,即使用手动注释或AI产生的高质量数据进行管理模型培训。但是,该方法在小型模型中有两个主要问题:域的概括不足:在看不见的情况下,很容易过度 - ART训练,其性能大大降低。表面的推理能力:倾向于是一种与真正的理解和推理相匹配的浅模式。该模型很难解决类似的问题,但是很难处理需要深思熟虑的复杂问题。图1。实验结果的分析。 。 。课程加强方法我们建议在奖励设计方面采用困难,以确保模型能力从基本任务到复杂的识别任务的稳定提高。通过系统的实验,我们发现基于培训的训练方法具有独特nefit可以改善域之外的一般模型。但是,在实践中,我们注意到一种重要的“砖墙现象”:小型模型在简单的任务中迅速发展,但在复杂的任务中找到瓶颈,甚至导致其掌握能力的破坏。 Barangaythis被揭示为对训练过程的暴力切除,最终导致该模型转换为次优溶液。为了打破这种瓶颈,我们从研究课程(CL)中汲取灵感。研究课程是一种培训策略,该策略逐渐将模型暴露于复杂任务的增加。我们建议一种课程训练范式(Curr-Reft)研究的课程风格,以确保模型的能力从基本任务到任务改进的复杂理性。这种创新的方法将有助于小型VLMS打破性能瓶颈,并获得与大型模型相当的识别能力,同时保持对部署友好型。纸标题:通过一项研究研究研究研究研究课程来加强一般和推理语言模型:https://arxiv.org/pdf/2503.07065开放来源:https://github.com/ding523/curr_reft(code)https:/code)通过基于下降的课程加强方法和自我改进方法,我们可以显着改善视觉语言模型(VLM)的推理和概述。重塑加强学习能力的理论和实验分析:我们表明,基于规则的研究可以有效地重塑多模式/CV活动,从传统罚款转移到罚款。提高理解和一般性的能力:实验的结果表明,增强方法将显着改善分布式释放数据中的VLM性能。创新框架Curr-Reft:我们提出了一个新的训练后范式,将课程REI结合在一起Norcection技术和自我完善技术。它的有效性已在QWEN2.5-VL-3B和QWEN2.5-VL-7B模型中得到了证明。与基于自我和权威基准构建的许多数据集相比,对实验进行了全面分析,以验证模型的整体性能。结果表明,7B模型甚至超过最新的InternVL2.5-26B和38B型号。具体程序图2。培养后训练范式的建议的一般框架。 Curr-Reft包括两个连续的训练阶段:1.USO:通过与任务的复杂性相对应的奖励机制逐渐提高了工作的难度。 2。基于拒绝拒绝的自我改进:维持LLM模型的基本功能。 Curr-Reft包括连续的两个培训阶段:课程的加强研究:通过设计贫困的奖励并逐渐从BA移动,确保模型的能力稳定改善SIC对复杂推理活动的视觉感知。基于改进的自我调整I改进:通过从高质量的多模式和语言样本中进行选择性研究来维持VLM的基本功能。图3。培训培训数据培训数据。 (a)课程增强学习的渐进响应格式的三个阶段的示例。显示了从简单到困难的逐步工作过程,显示了不同阶段的响应格式的变化。 (b)SFT阶段中使用的数据资源的分布拒绝采样。阶段1:课程研究(课程研究(CL)是一种基于教学的培训方法。奖励贫困的机制,它与任务进度的自然路径相对应,该方法特别包括三个渐进阶段:二进制决策成功地实现了优化视觉感知和与复杂工作相对应的机制的稳定过程,这是系统的系统。综合数据集。在检查中包括:准确性,逻辑一致性,规范性格式和语言效率。在0-100点范围内审查了所有响应。分数超过85点的答案及其相应的问题包含在增强的数据集中。最终的组合数据集包含1,520个质量样本,涵盖了不同领域:数学,科学和一般情况的一般知识。数据分布如下:1。数学字段(700个数据):多模式数据(300件):geometry3k_mathv360k(100件)geo170k_qa(100件)(100件)geomverse(100件)(100件)纯文本数据:SK1.1数学问题(400件)_(400件)_(220件)。片段)纯文本数据:SK1.1科学问题(100件)3。一般知识领域(总计500个数据)多模式datadata):Illava_COT_100K(300件)Visual7W(100件)VSR(100件)VSR(100件)实验resuLTS验证我们的多模式多模式推理,我们进行了广泛的实验并在许多基准数据集上进行了测试。以下是对实验组件的详细介绍:实验设置1。视觉数据集我们建立了一个全面的审核框架,涵盖了三个主要任务:视觉检测,视觉分类和多模式数学推理,以评估研究视觉语言模型的视觉模型的有效性和整体功能。视觉检测:使用Refcoco和RefGTA数据集。视觉分类:使用RefCOO,Refcocog和Pascal-VOC数据集。多模式数学推理:MATH360K,GEO170K和CLAILC-70K计数数据集的集成。 2。基准测试我们在许多基准基准数据集中审查模型性能,包括:Mathvisa:综合数学基准。数学:高中竞赛水平的数学问题。 AI2D:主要的学校科学图表和相关问题。 mmvet和mmbencH:多模式能力的复杂推理和评估。实验结果我们已经显示出在多模式活动中使用Curr-Reft训练的模型的性能的显着改善,尤其是在跨域概括能力和复杂识别活动中。与传统的管理微调(SFT)方法相比,我们的方法不仅提高了准确性,而且Pinththe模型处理无形数据的能力也很好。下表显示了与域和外域各种训练技术的性能的比较。具体而言,它包括两种方法:传统上管理的微调(SFT)和增强(RL)研究:从这些实验结果中,可以看出,刺激性学习的方法(RL)具有重大的好处,可在改善高收入数据的内域内和外域模型性能方面具有重大好处。视觉数据集中不同技术模型的测试结果如Fwollows:验证逆转概括,而不是在多模式结构域中软化模型的能力。基准上不同方法模型的测试结果如下(评估集裁判模型使用GPT-3.5):总结本研究重点是在两个关键方面提高小规模视觉模型(VLMS)的性能:推理能力和外交(OOD)通用性能。通过实证研究,我们发现研究强化不仅可以有效地提高模型推理能力,而且还显示出超出视觉活动期望的概括性能的改善。基于这一重要发现,我们提出了一种基于微调(Curr-Reft)研究的基于课程的研究的创新后培训范式。这种方法是渐进式课程研究和拒绝刺伤技术的惊人混合。成功实现的retreft是两个BA的模型性能的重大改进SIC机制:增加任务的复杂性:高质量样本的选择性研究。
本文的第一组是中国科学技术大学的硕士和医生研究Huilin Deng。他的研究方向是多模型的视觉理解,增强的推理(R1研究)和异常发现。在Tai,Tase,ICCV以及其他期刊和会议等期刊上发表论文。近年来,随着大语言模型(LLM)的快速发展,多模式理解领域产生了前所未有的发展。诸如OpenAI,InternVL和QWEN-VL系列之类的最先进的视觉模型显示了处理复杂的视觉文本任务的剩余功能。但是,这些成就主要取决于大型模型的扩展(32B参数),从而在环境中产生了巨大的障碍。因此,如何通过有效的训练后范式缩小小型多峰模型和大型模型之间的性能差距是紧迫的PROblem。当前,VLM中的主要培训方法是通过微调(SFT)管理的,即使用手动注释或AI产生的高质量数据进行管理模型培训。但是,该方法在小型模型中有两个主要问题:域的概括不足:在看不见的情况下,很容易过度 - ART训练,其性能大大降低。表面的推理能力:倾向于是一种与真正的理解和推理相匹配的浅模式。该模型很难解决类似的问题,但是很难处理需要深思熟虑的复杂问题。图1。实验结果的分析。 。 。课程加强方法我们建议在奖励设计方面采用困难,以确保模型能力从基本任务到复杂的识别任务的稳定提高。通过系统的实验,我们发现基于培训的训练方法具有独特nefit可以改善域之外的一般模型。但是,在实践中,我们注意到一种重要的“砖墙现象”:小型模型在简单的任务中迅速发展,但在复杂的任务中找到瓶颈,甚至导致其掌握能力的破坏。 Barangaythis被揭示为对训练过程的暴力切除,最终导致该模型转换为次优溶液。为了打破这种瓶颈,我们从研究课程(CL)中汲取灵感。研究课程是一种培训策略,该策略逐渐将模型暴露于复杂任务的增加。我们建议一种课程训练范式(Curr-Reft)研究的课程风格,以确保模型的能力从基本任务到任务改进的复杂理性。这种创新的方法将有助于小型VLMS打破性能瓶颈,并获得与大型模型相当的识别能力,同时保持对部署友好型。纸标题:通过一项研究研究研究研究研究课程来加强一般和推理语言模型:https://arxiv.org/pdf/2503.07065开放来源:https://github.com/ding523/curr_reft(code)https:/code)通过基于下降的课程加强方法和自我改进方法,我们可以显着改善视觉语言模型(VLM)的推理和概述。重塑加强学习能力的理论和实验分析:我们表明,基于规则的研究可以有效地重塑多模式/CV活动,从传统罚款转移到罚款。提高理解和一般性的能力:实验的结果表明,增强方法将显着改善分布式释放数据中的VLM性能。创新框架Curr-Reft:我们提出了一个新的训练后范式,将课程REI结合在一起Norcection技术和自我完善技术。它的有效性已在QWEN2.5-VL-3B和QWEN2.5-VL-7B模型中得到了证明。与基于自我和权威基准构建的许多数据集相比,对实验进行了全面分析,以验证模型的整体性能。结果表明,7B模型甚至超过最新的InternVL2.5-26B和38B型号。具体程序图2。培养后训练范式的建议的一般框架。 Curr-Reft包括两个连续的训练阶段:1.USO:通过与任务的复杂性相对应的奖励机制逐渐提高了工作的难度。 2。基于拒绝拒绝的自我改进:维持LLM模型的基本功能。 Curr-Reft包括连续的两个培训阶段:课程的加强研究:通过设计贫困的奖励并逐渐从BA移动,确保模型的能力稳定改善SIC对复杂推理活动的视觉感知。基于改进的自我调整I改进:通过从高质量的多模式和语言样本中进行选择性研究来维持VLM的基本功能。图3。培训培训数据培训数据。 (a)课程增强学习的渐进响应格式的三个阶段的示例。显示了从简单到困难的逐步工作过程,显示了不同阶段的响应格式的变化。 (b)SFT阶段中使用的数据资源的分布拒绝采样。阶段1:课程研究(课程研究(CL)是一种基于教学的培训方法。奖励贫困的机制,它与任务进度的自然路径相对应,该方法特别包括三个渐进阶段:二进制决策成功地实现了优化视觉感知和与复杂工作相对应的机制的稳定过程,这是系统的系统。综合数据集。在检查中包括:准确性,逻辑一致性,规范性格式和语言效率。在0-100点范围内审查了所有响应。分数超过85点的答案及其相应的问题包含在增强的数据集中。最终的组合数据集包含1,520个质量样本,涵盖了不同领域:数学,科学和一般情况的一般知识。数据分布如下:1。数学字段(700个数据):多模式数据(300件):geometry3k_mathv360k(100件)geo170k_qa(100件)(100件)geomverse(100件)(100件)纯文本数据:SK1.1数学问题(400件)_(400件)_(220件)。片段)纯文本数据:SK1.1科学问题(100件)3。一般知识领域(总计500个数据)多模式datadata):Illava_COT_100K(300件)Visual7W(100件)VSR(100件)VSR(100件)实验resuLTS验证我们的多模式多模式推理,我们进行了广泛的实验并在许多基准数据集上进行了测试。以下是对实验组件的详细介绍:实验设置1。视觉数据集我们建立了一个全面的审核框架,涵盖了三个主要任务:视觉检测,视觉分类和多模式数学推理,以评估研究视觉语言模型的视觉模型的有效性和整体功能。视觉检测:使用Refcoco和RefGTA数据集。视觉分类:使用RefCOO,Refcocog和Pascal-VOC数据集。多模式数学推理:MATH360K,GEO170K和CLAILC-70K计数数据集的集成。 2。基准测试我们在许多基准基准数据集中审查模型性能,包括:Mathvisa:综合数学基准。数学:高中竞赛水平的数学问题。 AI2D:主要的学校科学图表和相关问题。 mmvet和mmbencH:多模式能力的复杂推理和评估。实验结果我们已经显示出在多模式活动中使用Curr-Reft训练的模型的性能的显着改善,尤其是在跨域概括能力和复杂识别活动中。与传统的管理微调(SFT)方法相比,我们的方法不仅提高了准确性,而且Pinththe模型处理无形数据的能力也很好。下表显示了与域和外域各种训练技术的性能的比较。具体而言,它包括两种方法:传统上管理的微调(SFT)和增强(RL)研究:从这些实验结果中,可以看出,刺激性学习的方法(RL)具有重大的好处,可在改善高收入数据的内域内和外域模型性能方面具有重大好处。视觉数据集中不同技术模型的测试结果如Fwollows:验证逆转概括,而不是在多模式结构域中软化模型的能力。基准上不同方法模型的测试结果如下(评估集裁判模型使用GPT-3.5):总结本研究重点是在两个关键方面提高小规模视觉模型(VLMS)的性能:推理能力和外交(OOD)通用性能。通过实证研究,我们发现研究强化不仅可以有效地提高模型推理能力,而且还显示出超出视觉活动期望的概括性能的改善。基于这一重要发现,我们提出了一种基于微调(Curr-Reft)研究的基于课程的研究的创新后培训范式。这种方法是渐进式课程研究和拒绝刺伤技术的惊人混合。成功实现的retreft是两个BA的模型性能的重大改进SIC机制:增加任务的复杂性:高质量样本的选择性研究。 - 上一篇:建议哪种软件培训游戏?软件培训游戏的最新排
- 下一篇:没有了